Style transfer is an interesting task to do, as it contains the basic ideas in image processing which is popular in model mobile apps. It is also a project that worth stressing in computer vision classes. In this post, we implemented a style transfer CNN on the top of the pre-trained VGG-16 or VGG-19 models. To achieve the goal of style transfer, two loss functions are utilized to optimize the neural network: the style loss and the content loss. By adjusting the ratio of these two loss functions, the user is able to control the degree of style transference.
About Style Transfer
In this system, we will take two images as input and one image as output whose style is similar to one of the inputs while content closest to another. In the article A Neural Algorithm of Artistic Style, the authors actually thought this is the way to create arts, by imitating someones style and changing the content. A step further, this may actually ability for a network to merge the style of serveral artists and create its own style which is kind of similar to students learning from masterpieces by copy painting.
Here is an example I generated from this model with image of ‘Deadpool in Civil War’(Image source: theodysseyonline.com) and combine it with the style of Guernica by Picasso (1937).


Then the output after style transfer is
![]()
We can also apply the style of famous Starry Night by Van Gogh

CNN Structure
The most significant difference the style transfer CNN has with other image classification networks is that it has two inputs: the style image and the content image. Thus there will be two loss functions, one to measure the distance between the generated image and the desired content, and another to measure the distance between output and the style we want.
Then how to represent the conten and style of an image? In the above article, the authors pointed out the input image of a CNN is transformed into representations that increasingly care about the actual content of the image along the processing hierarchy. To obtain the style of an image, we include the correlations of multiple layers of input image, which captures its texture information.
Here we use the already well trained VGG-19 layer model as the baseline to infer style and content information from a picture. The structure of the CNN is like:
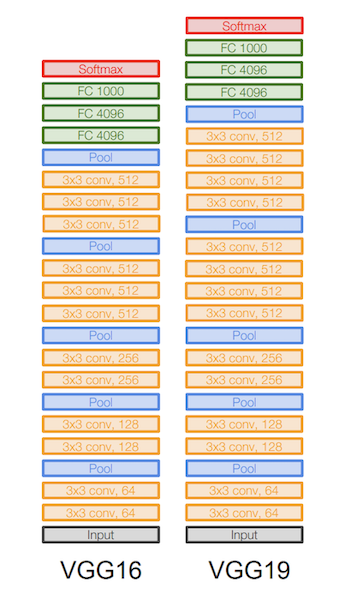
(From: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf)
The layers of ‘conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’,and ‘conv5_1’ are used as content layers to extract content features of different dimensions. Each of the above layers has defined a series of filter banks which varies with the postion of the layer in the network. We assume layer (l) has number of $N_l$ filter and each filter has dimension of $M_l$. If the original image is $p$ and generated image is $f$, the square loss of content layer $l$ is defined as: \(\begin{align*} L_{content}(p,g,l)=1/2 (\Sigma_{ij} (G^l-P^l)_{ij})^2 \end{align*}\) Where $F^l$ and $P^l$ is feture map of generated and original image respectively.
We can use feature correlations between features to represent the style of an image, which is given by Gram Matrix $G^l\in R^{N^l N^l}$ where $G^l_{ij}$ is the inner product between the feature maps $i$ and $j$ in layer $l$:
$G^l_{ij} = \Sigma F^l_{ik} F^l_{jk}$
Then the style loss of generated image is defined as: \(\begin{align*} E_l = \cfrac{1}{4N_l^2M_l^2}\Sigma_{ij}(G_{ij}^l-A_{ij}^l)^2 \end{align*}\)
\[\begin{align*} L_{style}(g,a) = \Sigma w_lE_l \end{align*}\]The total loss is \(L_{loss}(p,g,a) = \alpha L_{content}(p,g)+\beta L_{style}(g,a)\) Where $\alpha$ and $\beta$ are weights of different loss functions respectively.
Other Hyperparameters
We rebuild the VGG-19 layer model as our network and load weights from file as initialization. We used tf.train.AdamOptimizer as our optimizer to minimize total loss function. The content loss weight of each conten layer is set as [0.5, 1.0, 1.5, 3.0, 4.0]. The conten loss weight $\alpha$ is set as 0.01 while style loss weight $\beta$ is set as 1. Learning rate in this case is set as 2.0 while it does not matter too much in this case except affecting the rendering rate of original image.
The full code is here: https://github.com/bruceyoungsysu/style_transfer
Reference: https://github.com/chiphuyen/stanford-tensorflow-tutorials/tree/master/assignments/02_style_transfer