In this post, we proposed a two-stream wavelet transformation network based on the popular two-stream convolutional networks. Before going into the concept of the two-stream wavelet network, we will going through an application of how it can be used on CNNs in the area of action recognitions in videos. The key idea is to feed two streams of data into two separate CNNs: spatial stream that models scene and object contexts, while temporal-stream likely provides some motion-based attentions on foreground actions.
Two Stream Convolutional Networks
Karen et.al. proposed this network in their paper “Two-Stream Convolutional Networks for Action Recognition in Videos”. The authors thought RGB frames in video usually provide scene and object contexts in the background together with the human forms in the foreground. But the spatial area occupied by the human foreground is usually much smaller than the area of the background such that it might not be effectively represented. On the other hand, it can be depicted as “the spatial stream performs action recognition from still video frames, whilst the temporal stream is trained to recognise action from motion in the form of dense optical flow”.
In the paper both of the stream are implemented as ConvNets. Decoupling the spatial and temporal nets also allows the authors to exploit the availability of large amounts of annotated image data by pre-training the spatial net on the ImageNet challenge dataset.
The network structure provided in the paper is as following:
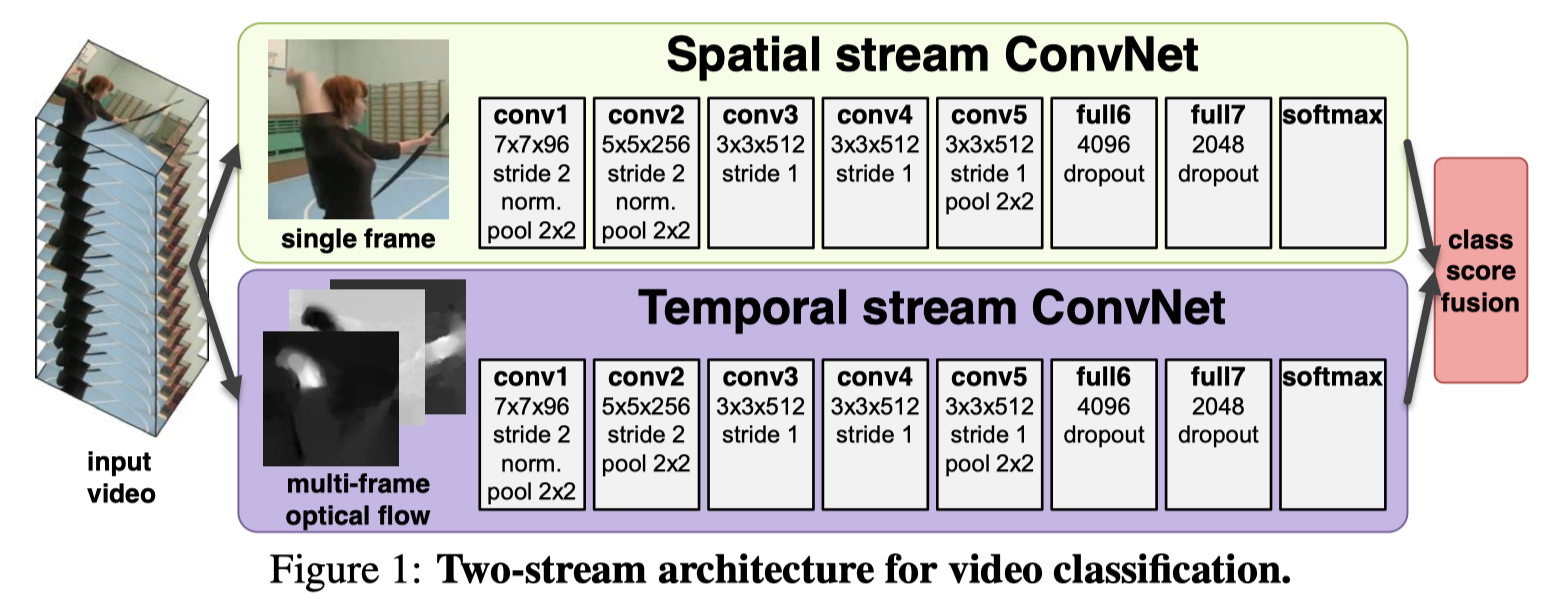
For detailed training parameters and results, please refer to this paper.
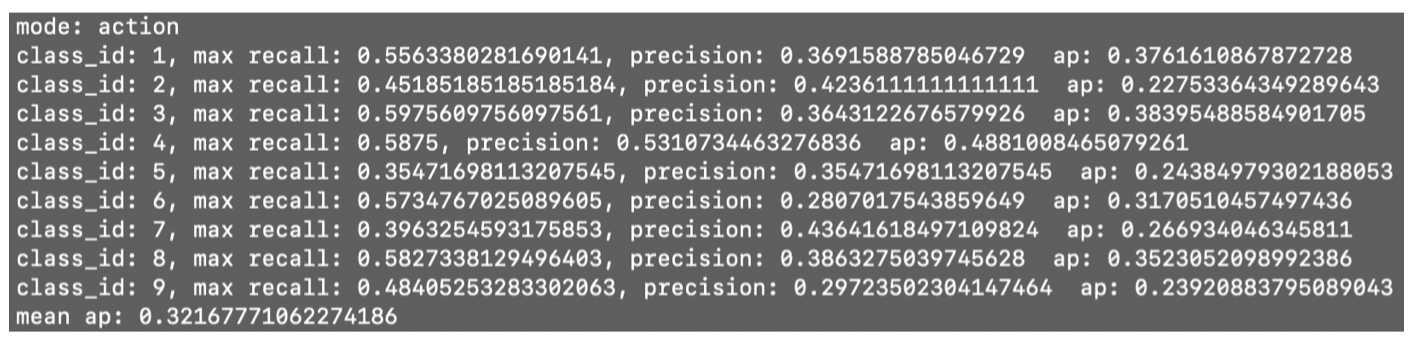
We also trained this two-stream CNN on an actor-action dataset to recoginize both celebrities and thier actions in some short movies. The result is comparable to other network structures. The actor recoginition has a precision of near 70% while action recognition has only 30% accuracy. It makes sense that action recognition is much harder than actor recognition.

Two Stream Wavelet Network
Wavelet transform (WT) is a robust and efficient spectrum analysis method. It inherits and develops the idea of localization of short-time Fourier transform. At the same time, it overcomes the shortcomings of window size and frequency variation, and can provide a change with frequency.
The Time-Frequency window is an ideal tool for signal time-frequency analysis and processing. Its main features are that it can fully highlight some aspects of the problem through transformation, can localize the analysis of time (space) frequency, and gradually multi-scale the signal (function) through the telescopic translation operation, and finally reach the high frequency. Time subdivision, frequency subdivision at low frequency, can automatically adapt to the requirements of time-frequency signal analysis, so that it can focus on any detail of the signal, solve the difficult problem of Fourier transform, and become a major breakthrough in scientific methods since the Fourier transform.
We proposed a two-stream action recognition network based on the wavelet convolution network proposed by Fujieda et.al. which is shown in the following figure.
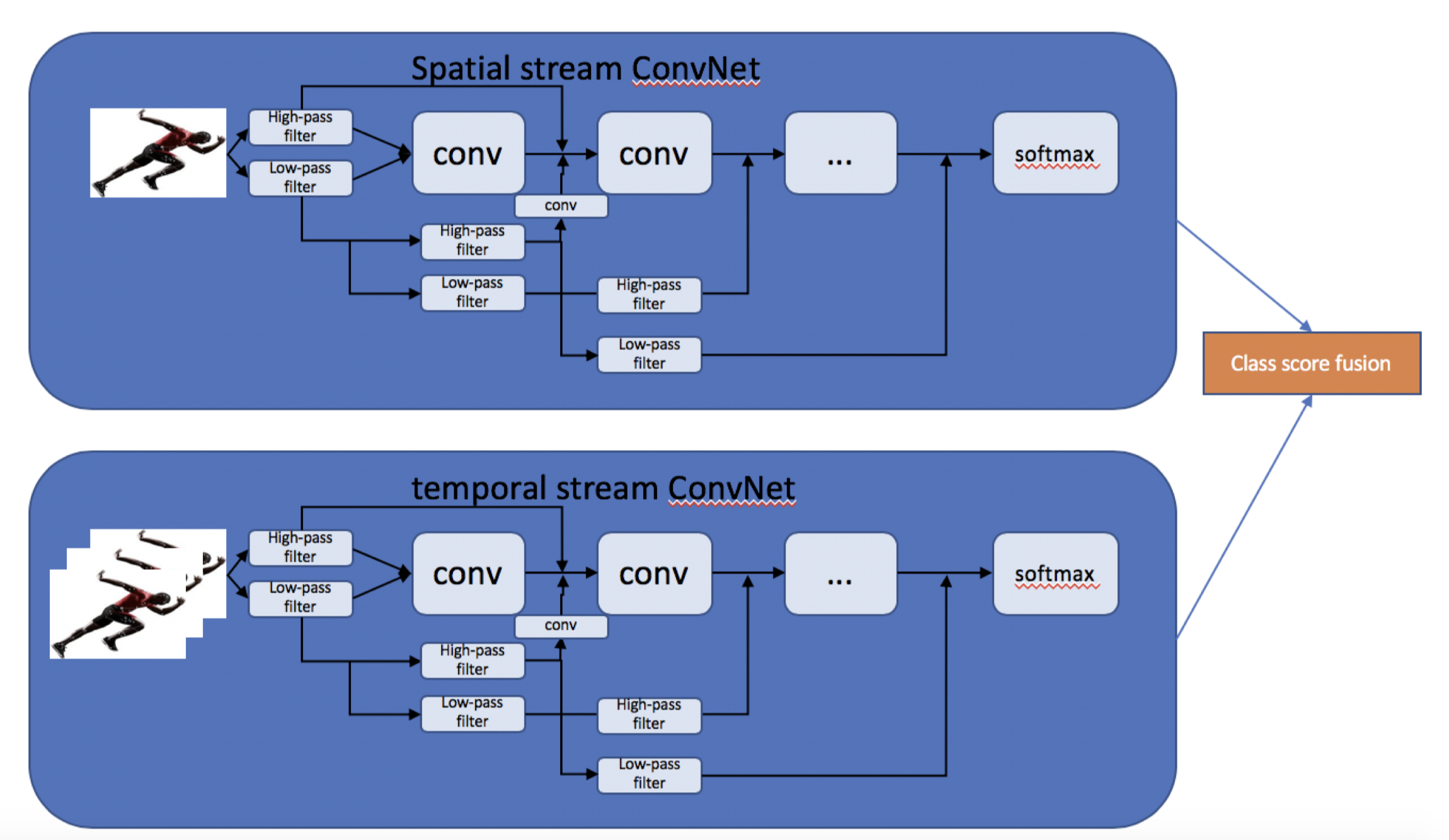
Wavelet CNN processes the input image through a group of low pass and high pass filters before feeding them into 3x3 convolution layers with 1x1 padding. By introducing another pair of high-low pass filters to the previous step high pass filter, it forms a multiresolution analysis system via wavelet transform inside this neural network architecture.
Note that we cannot use an arbitrary pair of filters to perform multiresolution analysis. For wavelet transform, the high pass filer is known as the wavelet function and the low pass filter is known as the scaling function.
As video is naturally composed of two parts: spatial and temporal components. The spatial part, in the form of static frames, carries information about objects carrying the actions in a video. The temporal part, in the form of optical flow between frames in our case, conveys the movement of the objects. Thus we devise our wavelet convolution network architecture accordingly, dividing it into two streams. Each stream is implemented using a bunch of convolution layers together with high-low pass filter pairs to reserve high frequency information. We consider the fusion methods of averaging on stacked normalized softmax scores as features.